The last months of the year have a particular rhythm in telecommunications. And this year more than ever.
When the FIFA World Cup is on the calendar, the whole sector knows there is a date that does not move: before it starts, everything has to be in production. What does not make it on time waits until after — and “after” means reaching year-end with the accumulated pipeline on top of you.
The result is the usual thing, but tighter: changes competing for the same windows, upgrades that depend on another project finishing first, migrations coordinated across several countries with different freezes and local teams with their own calendars — the same kind of friction I described when moving from a local team in Chile to coordination from Europe. Suddenly you are looking at a pipeline where everything is urgent, everything has dependencies, and in a few days you have to present the real status to management — without alarming them, but without hiding anything either.
The problem is not the amount of work. The problem is visibility. What comes first? What blocks what? Where is there a capacity conflict? Before answering any of those questions, you first have to build the picture. And that used to take days.
1. 🔍 The problem that lives between the tools
The tools are not missing. Jira for managing tasks, planners for organizing work, documentation that is theoretically up to date. The problem is that none of them tell you what happens over time — and in complex operations, that is exactly what you need to know.
Jira tells you what exists. Not when it goes, in what order, or what depends on what. It does not understand that if you have active projects in the backoffice that serves local services, you cannot run a complex upgrade of another component in parallel — because if something fails in production, nobody will know where the problem came from. That is not a minor detail. In production, traceability is everything.
Coordinating initiatives across several countries, with different platforms and local teams with their own rhythms and priorities, requires a view that no product on the market provides. Not a task list — a real read of what is in flight, what blocks what, where the real risk is, and how to communicate upward without alarming people and without hiding anything.
Then there are runbooks. A runbook is basically the step-by-step manual executed during a maintenance window — what the technical team does to implement a change in a controlled way. The problem is that over time they multiply: versions by country, numbered updates, variants by platform. Hundreds of Excel files that nobody knows for sure are current. Every window starts with hunting for the right file. It is a pain that has gone unsolved for years and has real consequences when something goes wrong.
2. 🛠️ What I built — and how it works
What I built has two parts that work together: a team portal and a planner.
The portal connects to Jira and gives visibility per project — from the EPIC down to the implementation task, with progress, planning, and status. But it goes beyond a Jira view. Each implementation task has its associated runbook, versioned, without Excel. There is a learnings section where what used to get lost in chats and emails is recorded. And you can export an executive summary with blockers and next actions, ready to share.
The planner is where I organize everything over time. I work with chain templates — basically a chain of tasks that defines everything that has to happen for something to be delivered. An upgrade follows its sequence: preprod, DR, prod batch 1, prod batch 2. A migration has its own. I can see several projects for the same country on the same timeline, move dates by dragging, and Jira updates on its own.
I built all of this with Claude — the same way I did with NeuraPRO — applying the same logic: understand the problem well before you start building.
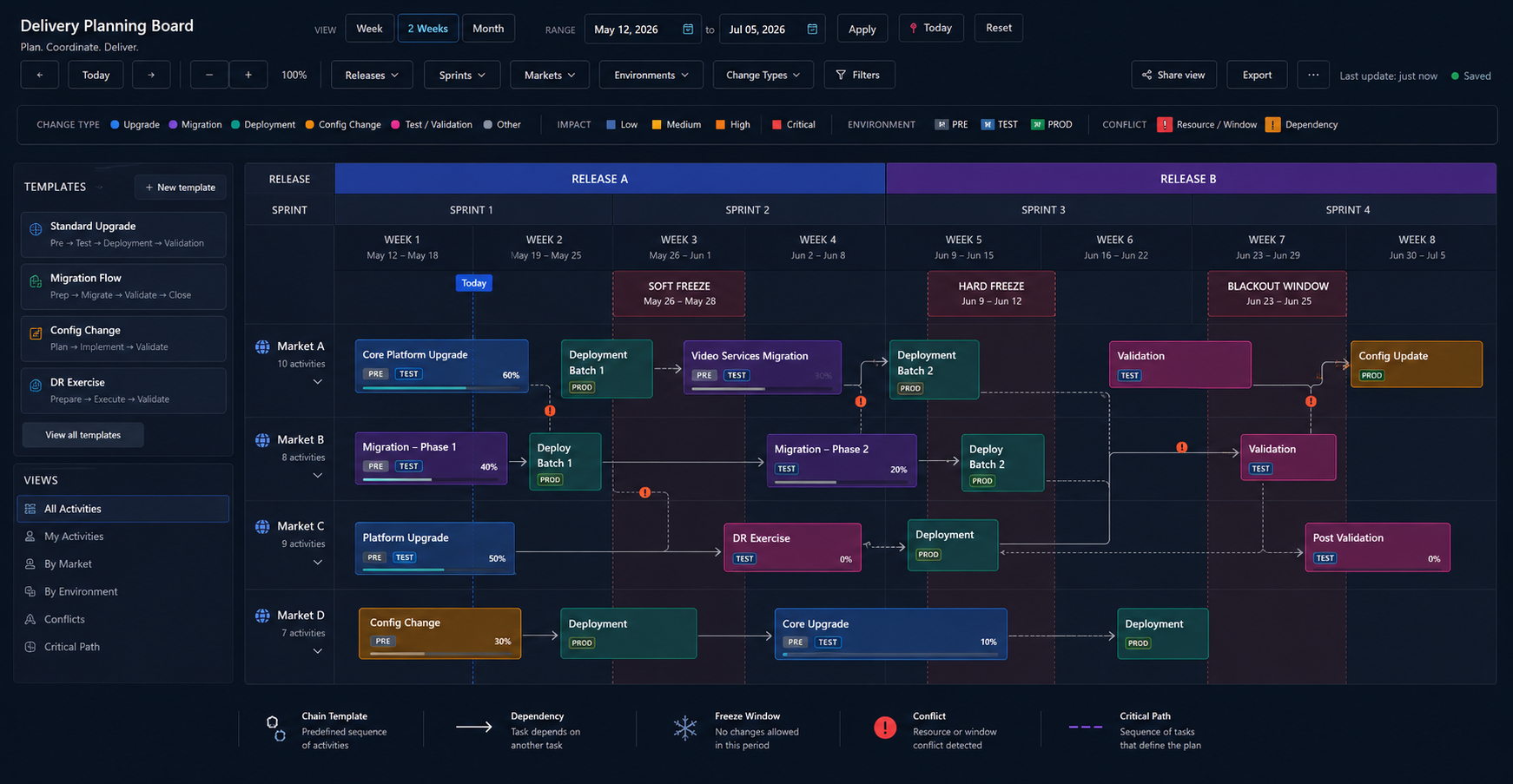
Illustrative image with sample data only. It does not show real operational information and does not expose private data from any market.
And on top of all this, Claude. An EPIC in Jira can have dozens of tasks, phases, dependencies, and acceptance criteria. Before, structuring all of that in a project took hours. Now, with Claude integrated directly in Jira, I can take an EPIC, analyze it, and turn it into organized chains and tasks — with its hierarchy, phases, and structure ready to go. I review, adjust what does not match the team’s reality, and execute.
From there, that structure moves into the planner. The team can see work spread over time, start prioritizing, spot conflicts, and talk about real risks — not dates dropped on a calendar without context.
Today I use it myself as the team’s technical project manager. First I want to get the most out of it in this stage — there is a lot in the pipeline and this is the moment to test and adjust. The next phase is opening it to the team with role-based access: each engineer with visibility of their tasks, their runbooks, and their progress, without everything having to go through one person.
A real example
In one market we had three critical projects running at the same time: two platform upgrades and a migration. Three EPICs in Jira, same country, same period.
Management was not asking if a window was available. They were asking what goes first and what has the most impact on production if something goes wrong.
In the planner all three show up as chain templates for the same country, on the same timeline. That is where you see what Jira does not: an engineer assigned to tasks on different projects the same day, a backup environment clashing with another activity, or a complex operation scheduled before earlier stages are validated. Without that visibility, if something fails in production you do not know where it came from.
The logic to order them was simple: preprod for all three first, then validation with the teams, then DR leaving at least one week between chains, and production order defined by how each one went in the earlier stages. If something fails, there is clear traceability.
When the issue is one person’s capacity, I filter by owner and see it immediately. For the management report, I export from the portal — dates, risk, status per project — without building a presentation from scratch.
3. ⚡ What changed
Yes, I save time. But that is not the main point.
Before, a lot of energy went into building the picture: pulling data from Jira, cross-checking information from different sources, trying to visualize somewhere which projects are in flight, what state they are in, who owns what, and when things clash. That is not program management — it is assembly. And when it takes days to put together, it is already outdated.
Now that time exists for what matters: does this project go first or second? Does the team have real capacity this sprint or just dates on a calendar? Is the risk we are seeing in one initiative related to something that already happened in another market?
As a program manager, the value is not knowing where each task sits. It is understanding how they relate to each other, what blocks what, and being able to communicate that clearly — to the team and upward. For that, you need the full picture, always updated. Before, building that picture was a job on its own. Now it is the starting point.
4. 🤔 What I keep turning over
The tool exists, works, keeps improving. But there are two things I cannot ignore.
The first: the same reasoning I used here works in any industry where there are processes and coordination. A mid-size hardware store. A pharmacy. A bakery with several locations. Not the large companies with IT teams — the ones with some technology but no idea where to start with AI. With a small group of people who know how to use AI, think clearly, and have worked under pressure, I think you can do quite a lot. The limit is not technical.
The second is more uncomfortable: in two or three years, at certain points in the chain there will be fewer and fewer people needed. Not as a prediction — as something already happening. What I built in weeks used to need a team and several months.
The issue is not whether to automate. It is at which point someone still needs to be watching — and how that gets decided. Today everyone resolves it as they can. At some point that will have structure: roles, policies, defined responsibilities.
What I do see from the inside is that the industry is still waiting for this to resolve itself. Very little real action. Management in many cases is still in observation mode, without fully understanding that the moment to experiment has passed — we are in the moment to build. And those who did not start will be late to that conversation.
✍️ Claudio from ViaMind
“Dare to imagine, create, and transform.”
Also available in Spanish: Cuando Jira no alcanza.
FEATURED POSTS
ABOUT ME

ViaMind Ecosystem
- ViaMind — The brand hub for ideas, technology and strategy.
- NeuraPRO — Practical software for managing real operations.